Hi there!
Thanks for choosing to visit this page, and my blog.
My name is Ashish, and I'm a bit of a wanderer when it comes to vocations. I'm not quite sure what I want to do with my life, and I'm not even sure that it is any one single thing.
But I know I like knowing about a lot of things, as many as possible. I know I like bike rides, I know I like the city I was born (Pune) and I know I like reading and writing.
Feel free to drop me a line if you feel like a chat - I'll look forward to it.
Cheers!
About a decade or so ago, my wife and I went out on a date. Because our daughter was a toddler back then, this didn’t happen all that often. But that day was a rare ol’ oasis: a meal (lunch) followed by a movie. What a treat!
And so lunch was had, and off we went to watch the movie. It is at this point, dear reader, that our little tale of love turns into one of horror.
For the movie that we had chosen to see on that fateful afternoon was a movie called Happy New Year.
There are no words in any known language that can describe how bad the movie was. Vogon poetry makes more sense than did the plot of that movie, and I wouldn’t blame the Vogons if they destroyed the planet all over again because of what I said.
But here, I tell my students when I narrate this horrible tale of horror in class, is where this turns into a teachable moment.
Within five minutes, I tell them, I and my wife knew that this movie was going to be crap. Actually, I’m lying, I tell ’em, because the other four minutes and fifty five seconds weren’t needed. I and my wife, I remind them – both of us with PhD degrees in economics. And even though we knew how bad the movie was, and even though we knew that sitting through it would be a complete, utter waste of our time – even then, dear friends, we sat and watched the whole damn thing.
I could have helped out at the popcorn stand outside, and that would have been a better use of my time. I could have stood on one leg in the men’s washroom for three hours, I say, and that would have been a better use of my time. I could have slapped myself for three hours – and I should have too, for having chosen this movie – and that would have been a better use of my time.
But because we had gotten the chance to go out after so long, I tell ’em, we stayed here and saw the whole damn thing.
A second, less obvious benefit is actively using the fallacy to your advantage. For example, many gym memberships require upfront payments regardless of how much you use the facilities. If you find it hard to ignore sunk costs, choosing gym memberships that have large upfront fees and minimal pay-per-usage fees may be a way to commit yourself to a regular gym habit.
This can also apply to other activities that involve short-term pain for long-term gain – for example, paying for an online course will make you more likely to stick with it than if you found a free course.
But be warned, this doesn’t work for everything: it seems that spending wildly on a wedding ceremony or engagement ring doesn’t have a “sunk cost” effect – it fails to increase the likelihood of staying married.
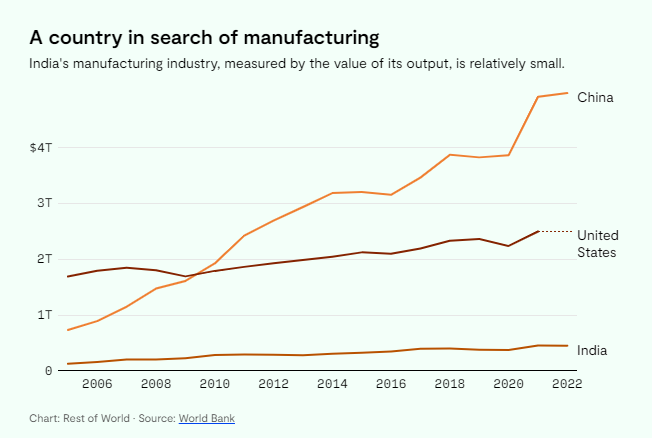
I wrote this just yesterday, that what “worked in the 1970’s for a village in India will work very differently for a city in China in the 2020’s”.
And as if to do me a favor, RestofWorld.com came out with a lovely story about Foxconn’s struggle to make iPhones in India. As always, please read the whole thing, but if you’re looking for great examples of why getting markets to work across time and space is difficult, this is a great example.
Lots of great takeaways, beginning with this chart:
But data and charts aside, this article is worth reading for fascinating little snippets on the intersection of culture and labor markets:
“In India, Apple’s suppliers have to contend with local policymakers, landowners, and labor groups. The country lacks China’s vast network of material and equipment makers, who compete for Apple orders by cutting their own margins. “Apple has been spoiled in China,” a senior manager at an Apple supplier, who was recently deployed from China to India, told Rest of World. “Here, except labor, everything else is expensive.””
Foxconn has hired women in Tamil Nadu for the most part, and this, it turns out, is how they started off in China as well. Women have, in China, moved now to “less arduous service sector jobs”.
“Hiring a young, female workforce in India comes with its own requirements — which include reassuring doting parents about the safety of their daughters. The company offers workers free food, lodging, and buses to ensure a safe commute at all hours of the day. On days off, women who live in Foxconn hostels have a 6 p.m. curfew; permission is required to spend the night elsewhere. “[If] they go out and not return by a specific time, their parents would be informed,” a former Foxconn HR manager told Rest of World. “[That’s how] they offer trust to their parents.””
“Foxconn also had to find a workaround for employing married women. The company typically requires workers to pass through metal detectors when entering and exiting its factories in order to prevent leaks about upcoming products, according to reports. But in India, married women wear a mangalsutra, a metal pendant; and a metti, a metal toe ring. These workers are searched manually and have their jewelry logged in a notebook.”
“They recounted how a Chinese Foxconn worker became frustrated with a junior Indian technician who repeatedly failed to solve a technical glitch. The Chinese worker fixed it himself and walked away. “He did not teach me,” the translator recalled the Indian worker saying timidly. “How many times should I teach?” the Chinese worker replied.”
The well documented opposition to the move to twelve hour shifts finds mention here, of course, but what I found particularly interesting was the fact that China has only eight hour shifts. Foxconn relies, the article says, on lax enforcement of the country’s labor law to get around this requirement.
Indian workers are getting acquainted with the neijuan culture, and the Chinese workers aren’t sure if this is, all things considered, a good thing.
I’ve met my share of Indians who don’t like to eat food from abroad while traveling, because it is too smelly/exotic/<insert adjective of choice here>. So when I read about Li, a Chinese worker in India being unable to stand the smell of Indian food, and it being “all yellow and mushy stuff”, I couldn’t help but chuckle.
This is probably my favorite bit from the entire article: “Both groups have picked up phrases from the other’s language. Sometimes an Indian colleague will greet Li with the common Chinese greeting, “Have you eaten yet?” To which Li will reply in Tamil, “I already ate.””
The article speaks about workers being able to convince their families to delay their marriages, because these workers are now the main bread-winners for their families… but on the other hand, the workers also mention in the same article their fears about being too old for the company to retain them. The age of the worker in question? 26.
And finally this anecdote: … “During the first week of October, the national holiday celebrating Mahatma Gandhi’s birthday fell on a Monday and created a rare two-day weekend for Foxconn employees. Li planned to visit the Taj Mahal. He would spend a good deal of the weekend in buses and airplanes, but figured it would be worth it — he wanted to have seen it before his time in India was up. But a few days before he was due to leave, Li had to cancel. Management had announced that the factory needed to stay open to meet targets. Sunday would be a workday.” … reminded me of this one from Studwell’s How Asia Works: “After the first steel was poured on 9 June 1973, Park Chung Hee declared an annual National Steel Day to go with the annual National Export Day he had inaugurated in 1964. This being Korea, these were working holidays.”
About three weeks ago, Gulzar Natarajan wrote a blogpost titled “25 economic orthodoxies that should be discarded“. The list is fascinating and worth thinking about. Doubly so if you are learning or teaching economics, and each of his twenty-five picks is worthy of discussion.
So worthy, in fact, that a blogpost probably won’t be enough – but it will be a good enough start, perhaps? Let’s find out, beginning with his first point: there are no free markets in the world.
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.
Economists look at the world, and try and make sense of it, by building the simplest possible system “that works”. To this system, they add increasing levels of complexity. At some point, they stop and say “Ah, this is now a working model of the world”. They then “run” this model, “see” what happens, and therefore predict what will happen in the real world. Sometimes the model “works”, in the sense that the model predicts, more or less, what actually took place in the real world. Sometimes the model fails, in the sense that the world goes and does something else altogether. The world is quite irritating that way.
In either case, we “update” the model, and we try again. And on and on we go.
But it all begins by building the simplest possible system.
How does this work, exactly?
Let’s say I want to stop writing this post, and I want to go have a cup of chai. Let’s model this simple statement.
I want to have chai.
But I’m a hopelessly lazy person, I don’t want to make chai. I simply want to go outside to a tapri, ask for a cup of chai, and sip on it.
We now have demand. There is a “rational agent”, who desires a particular commodity called chai. Do we have supply?
Sure we have supply! In fact, there is a lot of it – why, there are at least ten chai tapris a short stroll away from my house. Each of them will happily sell me a cup of chai for ten rupees. And, if I so desire, a packet of biscuits, or a cigarette to go with it. I desire neither, but that will not matter to the seller – they will happily sell me just the chai.
So now we have supply. And we have, therefore, a market for chai.
Gall’s Law, y’see. A simple, working model of a market. It’s easy, this economics-y stuff.
Just as there are no frictionless surfaces, there are no free markets in this world, ones that have perfect competition. Nor can there ever be any such markets. All markets, embedded as they are in the real world with people having widely varying and idiosyncratic preferences, suffer from imperfections and failures. The markets cannot self-correct these. Policy interventions are essential in those markets where failures impose significant social costs.
Is the market for a cup of chai close to where I stay perfectly competitive? That is, is the market that I just described “without friction”?
Am I indifferent to where I will have my chai? Will any one of the ten tapris do, or do I have a favorite? Of course I have a favorite, which self-respecting Indian doesn’t?! In the language of economics, the good in question (a glass of cutting chai) ain’t homogenous. I have preferences.
It’s weird, and it is a story worth the telling – I actually am indifferent to the chai in all of the ten tapris, but my favorite tapri sells vada pav as well, and ooh, there’s this one tapri has fantastic vada pavs. And I’ve made friends with the lady who runs that tapri, and whenever possible, she fries up a fresh batch of vadas whenever I turn up. And so I end up having chai there. Why do I bring this up? Because friction, because imperfection, because idiosyncrasy. This is already not a perfectly competitive market.
Are all ten chai tapris run equally efficiently? Are all run by folks equally proficient in running a chai tapri? What does being equally proficient mean, exactly?
Equally good at making a cup of chai? Maybe one of them puts green cardamom in their chai, maybe one of them puts ginger, and maybe a third puts a bit of both?
Equally good at dealing with the local politician or local cops? Maybe one of them speaks Marathi but another does not? Maybe one of them is from a particular religion, but the other is not? Maybe one of them speaks a particular language, but the other does not? Maybe one of them is from a particular gender, but the other is not? Maybe one of them is from a particular caste, but the other is not? Don’t these things matter? Of course they do.
One of these chai tapris is located next to a sports facility. Another is located right next to a building that has a lot of offices and shops. Another also sells vada pav. A fourth is closest to a mandir. Do preferences build differently over time within the same locality as a consequence? Of course they do.
Do all of them have access to the same quality and quantity of water, tea leaves, vessels and cups?
And so, for all of these reasons and so, so many more, the market for chai tapris right outside where I stay isn’t competitive.
I do not bring all of this up to show you that India in particular is imperfect, or that economic theory is hopeless. All societies the world over will have different preferences and constraints. And so both demand and supply, in any market, will have frictions and imperfections. And this is just the market for chai! What about the market for nuclear reactors? Covid-19 vaccines? Helicopters for the military? Software engineers? Milk? Votes? Kidneys?
These frictions and imperfections will mean that markets will not work as efficiently as they would have otherwise. And because they are not able to work as efficiently as they could have, the good in question is either not produced as much as it could have been, or is sold at a slightly higher price than it could have been, or both. And so either producers suffer, or consumers do, or both.
And all this before we talk about externalities, but that’s a whole other story.
Gulzar Natarajan’s first point in his list of things that don’t work in economics theory is that markets are not self-correcting. They don’t work perfectly.
And so, he says, “policy interventions are essential in those markets where failures impose significant social costs.”
Now, here’s where things get interesting, tricky and contentious, so make sure you follow along carefully:
Almost every economist I know will agree that markets are not entirely self-correcting. We can and do quibble about the extent and ability of self-correction in different markets, but that’s a debate about degrees. It is not a debate about the existence of perfectly competitive markets.
Almost every economist I know will agree that market failure, in some cases and for some markets, will impose significant social costs. That just is a fact. Again, the debate is about degrees, not about the fact that these social costs exist.
But those four simple words… “policy interventions are essential”… that is where the debate rages. If economic theory is Jupiter, this is our Great Red Spot.
Folks who support policy interventions will say “There is market failure! There are significant social costs!”
Folks who don’t support policy interventions will say “Nah, it’s not as bad as you think it is! See this study, and that one, and that one, and this RCT, and that one, and this RDD and that one!”
And folks who support policy interventions will publish 547 well-researched, impeccably cited and co-authored papers refuting the 389 well-researched, impeccably cited and co-authored papers saying it wasn’t as bad as you thought, and well, this never stops. Avoid getting sucked into these battles, unless you like doing this sort of thing, or need to publish in order to get a degree or a promotion.
Bu even if both the pro-interventionists and the anti-interventionists agree about the presence of significant social costs, the story is very far from over. Because all that we have managed to do is agree upon the diagnosis. Not the cure!
“Market failure leads to social costs leads to policy intervention and so QED”, say the pro-interventionists. “Not so fast!”, say the anti-interventionists. “Who, exactly, is going to guarantee that the intervention will not make things worse? You and what army?”
“So which is it?”, you may well ask. “Do interventions make things worse, or better?”
I’m positively delighted to inform you that the answer to this question is dependent on time, place and scale. So a policy intervention that worked in the 1970’s for a village in India will work very differently for a city in China in the 2020’s. So we just don’t know for sure.
Bottomline: yes, of course there is market failure. Measuring the extent of it, and its impacts, is tricky. Yes, thinking about interventions is necessary. Coming up with the best possible design and the best possible implementation for these interventions is tricky. Measuring (let alone predicting) their first and second order effects is impossible.
Bottom-er line: Folks who say markets always work are wrong. Folks who say interventions always make things better are wrong.
Half the width of the footpath is for businesses, and this is formally/informally understood. The reason for the “/” is that in some cases, there is a white line running along the length of the footpath that kinda sorta officially sets the boundary.
The other half is not necessarily always for walking, it can be used for parking too. In this sense, walking in Hanoi was very similar to walking in India. Some cafes actually have little wooden blocks that are kept adjacent to the footbath, so that bikes can be pushed onto the footpath. Can be used by paying customers of the cafe only, of course.
Traffic is as chaotic as India, but pedestrians assume that the vehicles will stop for them (and they do). Here, of course, it is the other way around.
Coffee rules. I approve. We stayed next to a lake, and sitting on one of those small chairs and sipping on black coffee is a wonderful way to spend an hour or so.
I couldn’t help but wonder if the word “banh” comes from “pain” in French, which means bread. But apparently not.
The drop-off in quality of visible infrastructure is as startling as it is in India. You know how the areas around where the bigwigs stay and immediately outside the airport in your city are much better than the neighbourhoods where aam janta stays? Hanoi is exactly like that, but marginally cleaner.
You can’t go wrong with the food, and in more ways than one. Almost all of the stalls and shops along the main roads and with fronts opening up on the streets are tourist friendly, and the food is excellent.
When I say tourist friendly, I don’t mean to say the rest of the city is not friendly. I mean the dishes are tourist friendly. Which is why a food tour is recommended – because you’ll never get to even see some of the more “hidden” places. If you’re feeling adventurous, try the balut. I did, but couldn’t manage more than one bite.
There is a lot more to Vietnamese cuisine than just the pho and the banh mi, and the best way to learn about it is to walk, mostly through the old part of town. Walking is also the best way to experience the city.
The higher the rating for a place on Google Maps, and the more the number of ratings, the more likely it is that the place is a favorite with tourists. This is a good example, but there are many such places. This will be good food, but it won’t be truly Vietnamese. It will be a somewhat decent version of heavily touristified Vietnamese cuisine.
But when you’re traveling with a ten year old, that may not be a bad thing. What are you optimizing for?
But while walking to your restaurant of choice, feel free to stop and try as much of the food from the street side shops as you possibly can. Surprises abound on virtually every corner.
I observed shop-owners and friends sit down for a meal in their shops, or in front of their shops, on more than one occasion. A sense of community is palpable, and if not a meal, often a cigarette and a coffee, or a beer. Wonderful.
Staring at your phones isn’t a thing if you are in charge of a streetside shop. At least, isn’t as much of a thing as it is in India. Note that these things are hard to quantify!
Don’t order a dish for yourself in restaurants. Order, instead, lots of small dishes and share.
The food is not spicy. The flavors are, as a rule, more subtle than in, say, Thai cuisine, or Malay cuisine.
Don’t waste a meal by going into a truly fancy place. If your time is limited, have every single meal in as many local places as possible.
The Vietnamese National Museum of Fine Arts is well worth a visit, and you could easily spend half a day there, if not more. The ground floor and the third floor were my favorites.
Workers returning to the office and socialising after pandemic lockdowns helped lead to a 15% surge in sales of deodorants, according to the maker of Dove, Rexona and Impulse.
A friend is fond of pointing out and celebrating teachable moments, and I’m going to struggle to find better examples of complementary goods!
By the way, I’ll be in Vietnam this entire week, first in Hanoi and then in Hoi An, so food recommendations, and other tips – very much in that order – are very welcome.
This link was shared with me via a WhatsApp group which shares one interesting link a day, and the group is set up in such a way that only the admins can send messages. Social media done right, if you ask me.
IT sector has been growing quite rapidly. Nifty IT index was ~ 1000 in year 2000 and reached 20,100 in SEP 2023. 20X growth in 20 years. But the fresher salaries have stayed the same. Why?
I just wrapped up a semester of teaching at the Gokhale Institute. It is my favorite course (Principles of Economics) to teach, at my favorite place, so a bittersweet moment of sorts.
And the last class was an extended five random questions session, with lots of fun questions coming my way. One of which, it turns out, was a request for me to ask them a random question. Fun request, and here is what I have asked them:
“You get to redesign higher education from the ground up. All higher ed institutions are scrapped, and society, industry and academia will go along with the institutions, culture and regulations that you choose to construct/create to make higher education as good as it can possibly be – good itself being defined howsoever you like. What will you do, and why?”
They have all the time in the world to answer, and of course it is not mandatory to do so. But should you choose to answer, I would love to hear it! So please, do let me know the how, the what and they why of your proposal to change higher education in India for the better.
Happy Diwali, everyone!
(I hope to post everyday next week, but am very much on leave. We’ll see!)
Sisyphus was lucky to be given the task of pushing that boulder. If they really wanted to be cruel, they could have asked Sisyphus to write about India’s agricultural policies.
Given that a number of state elections are coming up, one can understand the central government’s overdrive to tame food inflation. Obviously, it does not want inflation to be an issue in election campaigns. But how we tame food inflation, and at whose cost, is important to analyse for rational policy making.
Thus begins Ashok Gulati’s recent column on taming food inflation in India – and it becomes angrier from there on in. And with good reason.
We now have a minimum export price on basmati rice, of $,1200 per tonne. The typical export price for this commodity for the last five years or so has been not more than $1,000 per tonne, so let’s call this what it really is: a ban on exporting basmati rice.
So if there is supply, and the government artificially curtails demand, what do you think will happen to the price? Who will get this lower price?
Plus, demand has been curtailed not in India, but abroad (say, for example, in Dubai). Who will help meet this demand in Dubai? Farmers in Pakistan – so it would seem the Indian government has put in place policies to help Pakistani farmers. Go figure. Here’s how Ashok Gulati puts it: “Externally, it must be remembered that it takes years to develop export markets, and by putting such a high MEP, India is basically handing over our export markets to Pakistan, who is the only other main competitor of basmati rice. Is this a conscious policy decision?”
There’s this rather depressing statistic in the piece: “It may be noted that in 2013-14, the last year of the UPA government, India’s agri-exports touched $43.27 billion, up from $8.67 billion in 2004-05 when it took over power at the centre. This is almost a five-fold growth in 10 years. If the same momentum had been maintained during the 10 years of NDA rule, agri-exports should have touched $200 billion. But in reality, they may not touch even $50 billion this year (2023-24).”
Finally, Ashok Gulati also points out that our R&D expenditure on agriculture is 0.5% of our agri-GDP. And that, as he says, is simply too small a number, and needs immediate doubling, if not tripling.
Very few things in life are as frustrating as analyzing India’s agricultural policies in general. And within this set of policies, our muddled thinking about agricultural exports takes the cake.