On Tuesday, I’d put up a post about Claudia Goldin having been awarded the Nobel Prize.
The original post did not have a chart at the start, it had a verbal description of a table from a rather-boring-to-read-but-oh-so-important PDF. A friend to whom I had sent the post for review suggested that a chart might do a better job instead. He was right, of course, and so I went ahead and added a chart. Here it is:

Here is the same data, but shown in a different way:
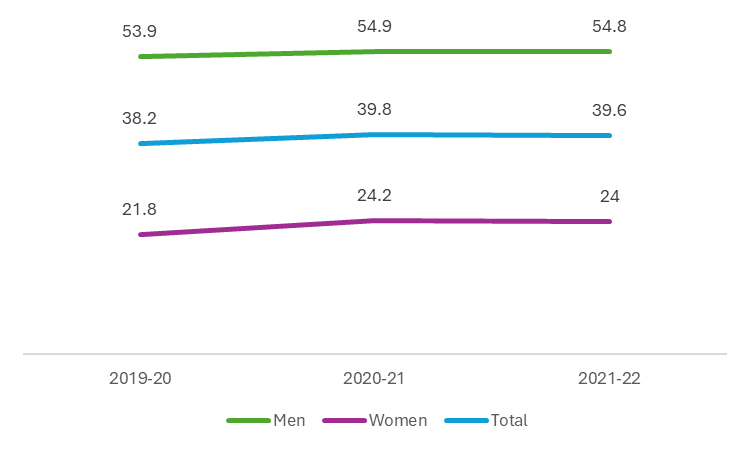
Which chart tells a better story?
Chart design and visualization is a subject that has long fascinated me. How long? 16 years, to be precise. One of my managers, back when I was a corporate employee, had taken a chart I had created, and shared it with the whole team. Which in and of itself was fine – but he had then also recreated my chart, but with his ideas for how to make it better. Placed next to each other, they showed pretty much the same thing – but in the same way that a stick figure and the statue of David are the same thing.
Now, I am nowhere close to being an expert when it comes to charts, but ever since that day, I have been fascinated by how powerful a well designed chart can be. Powerful in terms of it being a clear way to tell a story, it being a simple way to tell a story – and how much detail can be fitted into a single chart.
But for today’s post, let us focus on clarity and simplicity. Which of these two charts tells a simple, clear story? Would it be the one that I had in the post, or the second one?
- How do I want to group the data? Categories (men, women and total) on the axis, or time on the axis?
What story do I want to tell? Do I want to emphasize how much the data has changed over time, or do I want to make the point that women’s participation has always been lower than that of men (and of course therefore the total)? - Should I use bar charts, or should I use a line chart?
The answer to this question depends on the answer to the first question. If I want to emphasize how much the data has changed over time, it should be a line chart. If I want to emphasize the fact that women’s participation is always lower, I should use a grouped bar chart. But what if the line chart actually makes this point even more clearly? - Which color scheme is better?
Again, do I want to emphasize the difference between the categories? Or do I wish to emphasize the change over time. In my opinion, the second chart looks cleaner, and tells a simpler story. - Note that the second chart doesn’t have a reference scale, but the first one does (the “x-axis” with the numbers running from 0 to 60).
And therefore, to me, the second chart is better in this regard. It has less information that needs to be processed by the viewer, and they can reach a conclusion rather more quickly. - Do data labels help or hinder?
In my opinion, they help. In fact, well designed data labels take away the need for a reference scale, and so can help make the chart look cleaner. - What about chart titles?
Ideally, each chart should have a title, that answers the TMKK question. I didn’t include titles in either case because it was a blog post and not a presentation – but I know I would have got a metaphorical rap on the knuckles. When you create a chart, also create a useful title is a good rule to follow. So follow what I say, not what I do!
There are lots of good resources to follow online if you want to get better at using data visualization to tell better stories. Stephen Few, Edward Tufte, Jan Schultink and Nancy Duarte are just four names to get you started – but these four will teach you much more than you will need. And if you poke around in the alleys and bylanes of this part of the internet, you will be able to find so much more.
But please, do learn the art of data visualization, it is quite a powerful tool to have in your arsenal. And if you think the first chart is better than the second one, please let me know why – because I think the second chart wins hands down.

